# 例)csvファイルを読み込んで、必要な情報の列を選択し、p値でフィルタリングして、
# 変動が大きい順に並べ替えてから、csvファイルに書き出す例
path_to_input_csv |>
readr::read_csv() |>
dplyr::select(gene_name, treatment, fold_change, p_value) |>
dplyr::filter(p_value <= 0.05) |>
dplyr::arrange(desc(fold_change)) |>
readr::write_csv(file = path_to_output_csv)パイプ演算子を使う利点
ここではパイプ演算子を積極的に使用してコードを書くモチベーションとするために、 パイプ演算子を使用することによるいくつかの利点を紹介したい。
利点1(コードが見やすくなる)
前の項で説明した様に、パイプ演算子を使ってコードを記述すると読み取りやすくなる場合が多い。
以下では、ファイル読み込み、データ処理、ファイル書き出しを行う擬似的なコードを、 パイプ演算子を使って記述した。
このコードをパイプ演算子を使わずに無理やり書くと下のようになる。 非常にわかりにくく感じられると思う。
readr::write_csv(
dplyr::arrange(
dplyr::filter(
dplyr::select(
readr::read_csv(
path_to_input_csv
),
gene_name, treatment, fold_change, p_value
),
p_value <= 0.05
),
desc(fold_change)
),
file = path_to_output_csv
)- 1
-
dplyr::arrange()関数が現れるのはこの位置 - 2
-
dplyr::arrange()の第一引数 - 3
-
dplyr::arrange()の第二引数
また、これは次の利点にも関わることだが、パイプ演算子を使わずに書くコードでは 一つのデータ処理が行ごとにまとまっていない。 例えば、fold_change列の値で降順に並べ替える処理の記述は①と③の行に分かれてしまっている。 これもわかりにくさを助長する要因となる。
Tip
パイプ演算子を使うことで、見やすく理解しやすいコードを書くことができる。
利点2(処理の確認・修正が容易になる)
パイプ演算子を使ってコードを記述する利点は他にもある。
Rでデータ処理を行うコードを書くときには、試行錯誤をすることが多いだろう。 その様なときに、パイプラインの途中のデータの状態を確認したくなる場面は多い。
例えば以下のコードを例にして考える。
library(ggplot2)
# 前処理を行ったdata.frameを受け取って、散布図を描く関数
plot_points <- function(tbl) {
tbl |>
ggplot(aes(Sepal.Length, Sepal.Width)) +
geom_point(aes(color = Species), size = 3)
}
iris |>
tibble::as_tibble() |>
dplyr::select(Species, Sepal.Length, Sepal.Width) |>
dplyr::filter(Species %in% c("versicolor", "virginica")) |>
dplyr::mutate(Species = forcats::fct_rev(Species)) |>
plot_points()- 1
- この操作はいったい何をしているのだろうか?
①までのデータ処理を終えた中間結果を確認したいと思ったとき、どうようにすれば良いだろうか? これは簡単で、①のパイプ演算子前までを選択してコードを実行してみるか、 あるいは以下の様に①の次の行にreturn()を書いて、そこまで実行すれば良い。
選択範囲のコードを実行するには、RStudioならCtrl + Shift + Enterを押す(MacならCtrlではなく⌘)。
iris |>
tibble::as_tibble() |>
dplyr::select(Species, Sepal.Length, Sepal.Width) |>
return()
dplyr::filter(Species %in% c("setosa", "virginica")) |>
dplyr::mutate(Species = forcats::fct_rev(Species)) |>
plot_points()- 1
- このパイプ演算子の前までを選択して実行。
- 2
-
あるいは
return()を書いて、この行までを選択して実行。 - 3
- これらの行は実行しないように。コメントアウトしておいても良い。
Tip
return()をパイプ演算子の直後に書くことで、そこまでの途中結果を確認できる。
では次に、パイプライン中のある処理の有り無しで結果(出力される図)がどう変わるか確認してみよう。 下のコードの①②それぞれの処理をしない場合、結果はどう変わるだろうか? これを確かめるには、単にそれぞれの行をコメントアウトし、処理をスキップさせるだけで良い。
元のコードと実行結果は、
iris |>
tibble::as_tibble() |>
dplyr::select(Species, Sepal.Length, Sepal.Width) |>
dplyr::filter(Species %in% c("setosa", "virginica")) |>
dplyr::mutate(Species = forcats::fct_rev(Species)) |>
plot_points()- 1
- “”
- 2
- “”
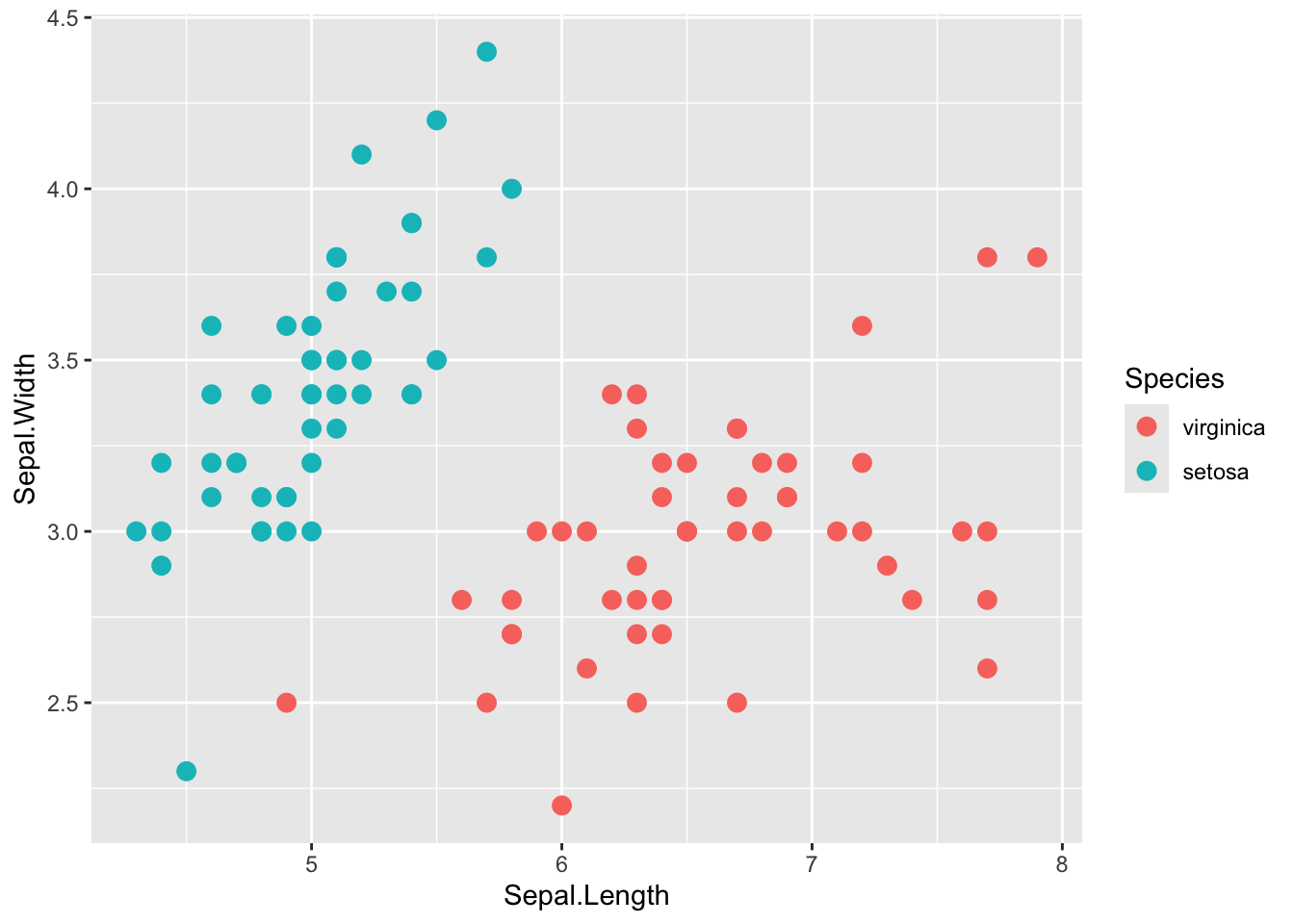
①をコメントアウト
iris |>
tibble::as_tibble() |>
dplyr::select(Species, Sepal.Length, Sepal.Width) |>
# dplyr::filter(Species %in% c("setosa", "virginica")) |>
dplyr::mutate(Species = forcats::fct_rev(Species)) |>
plot_points()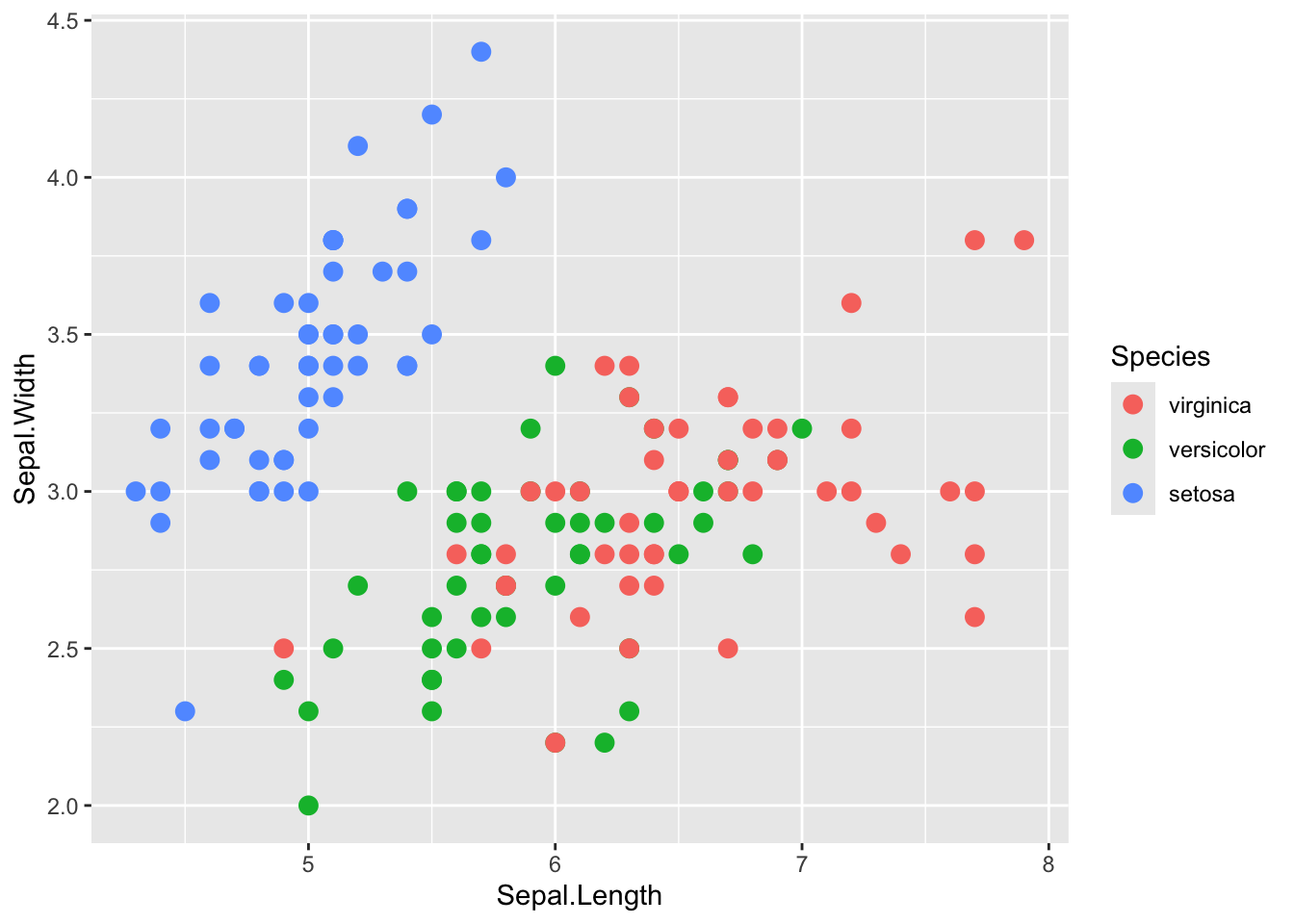
①をコメントアウトすると変数が一つ増えている。 つまりコメントアウトした行は、Species列の変数のうち setosaとvirginicaだけをフィルタリングする処理をしている。
②をコメントアウト
iris |>
tibble::as_tibble() |>
dplyr::select(Species, Sepal.Length, Sepal.Width) |>
dplyr::filter(Species %in% c("setosa", "virginica")) |>
# dplyr::mutate(Species = forcats::fct_rev(Species)) |>
plot_points()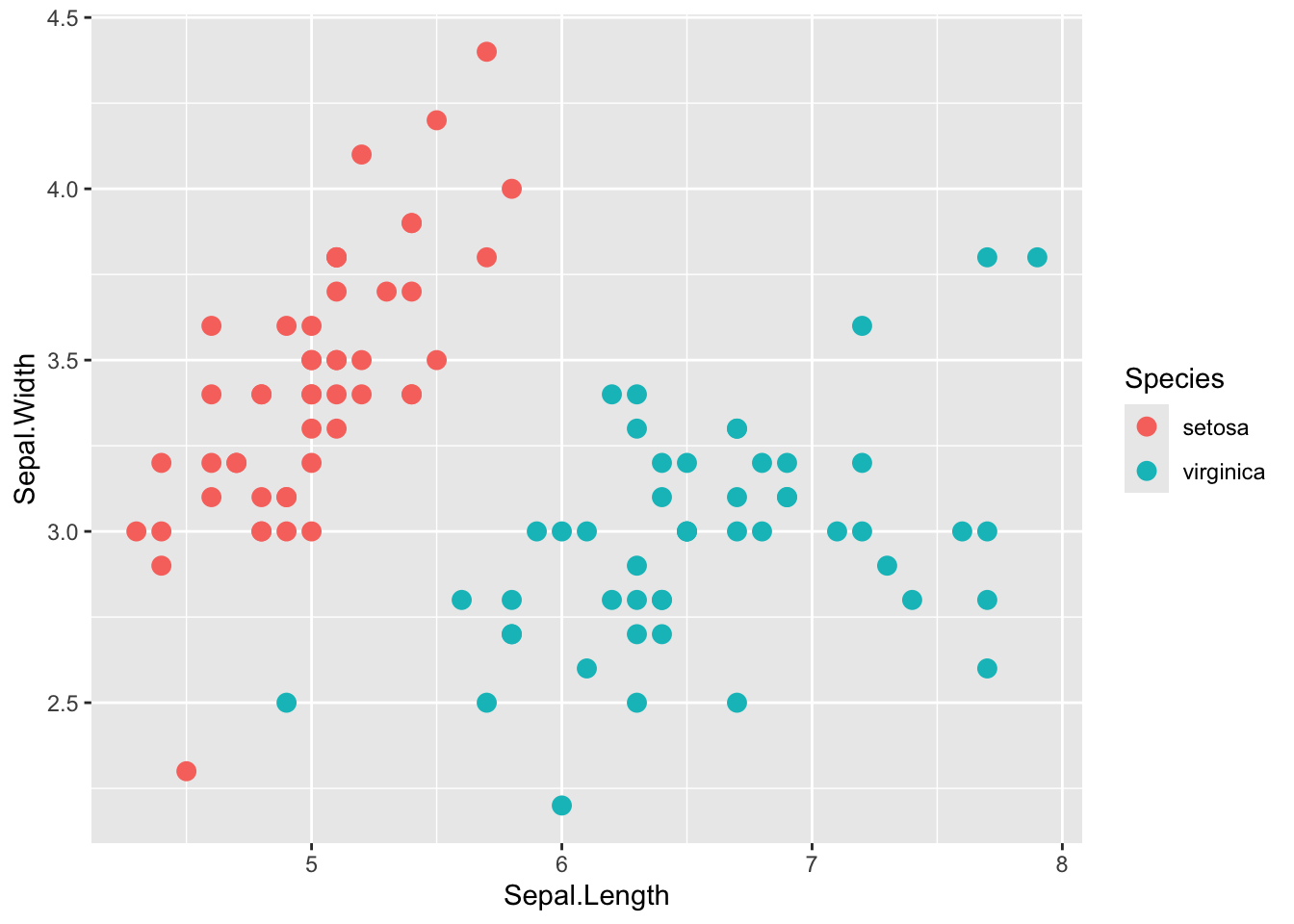
②をコメントアウトすると色が入れ替わる。 つまりコメントアウトした行は、Species列の変数の順序を決める処理をしている。
このように、パイプ演算子を使って書いたコードは行ごとに処理を分けて書くことができ、 それによって一部選択やコメントアウトを使うことで、 色々な処理を探索的に・簡単に試すことができる。
Tip
コメントアウトをうまく活用することで、簡単な変更・修正を探索的に試すことができる。
利点3(一行で複数の処理を書きやすい)
多くの場合、Rのコードはソースコードファイルに書いて記録し、 必要な部分を選択して実行する場合が多いと思う。 ここまでのパイプ演算子の利点はそういった場合、つまり改行して複数行のコードを書く場合の利点だった。
一方で、コンソールに直接簡単なRコードを打ち込んで実行する場合もあると思う。 コンソールにコードを打ち込む時は、普通改行は使用できないが、実はこのときにもパイプ演算子は便利である。
以下は、あるコードを書こうと考えた時のカーソルの位置(v)の変遷を示している(途中まで)。 見てわかる通り、前後に大きく行ったり来たりしている。 これはまだ関数を2つしか使おうとしていないので、より長い処理を書こうと思うと、 どんどんカーソルの位置の変更が大変になってしまう。
```{R console}
v
> iris
v
> iris
v
> dplyr::filter(iris
v
> dplyr::filter(iris
v
> dplyr::filter(iris, Species == 'setosa')
v
> dplyr::filter(iris, Species == 'setosa')
v
> dplyr::summarise(dplyr::filter(iris, Species == 'setosa')
v
> dplyr::summarise(dplyr::filter(iris, Species == 'setosa')
```- 1
- まず使うデータを打ち込む。(v: カーソル位置)
- 2
- dplyr::filter()を使ってフィルタリングしたい。カーソルを戻す。
- 3
- “dplyr::filter(”を追記。
- 4
- フィルタリング条件を書く。カーソルを先に進める。
- 5
- フィルタリング条件”, Species == ‘setosa’)“を追記。
- 6
- dplyr::summarise()を使って集計したい。カーソルを戻す。
- 7
- “dplyr::summarise(”を追記。
- 8
- 集計条件を書きたい。カーソルを先に進める。
一方でパイプ演算子を使って書くとどうなるか、以下のカーソルの動きを見てほしい。 パイプ演算子を使うことで、カーソルの前後の動きはほぼなくなり、 ただ必要な処理を順番に書いていくだけでよくなる。
```{R console}
v
> iris
v
> iris |> dplyr::filter(
v
> iris |> dplyr::filter(Species == 'setosa')
v
> iris |> dplyr::filter(Species == 'setosa') |> dplyr::summarise(
```- 1
- まず使うデータを打ち込む。(v: カーソル位置)
- 2
- dplyr::filter()を使ってフィルタリングしたい。“|> dplyr::filter(”を追記。
- 3
- フィルタリング条件”, Species == ‘setosa’)“を追記。
- 4
- dplyr::summarise()を使って集計したい。“|> dplyr::summarise(”を追記。
これは、コンソールで複数の関数を使用した長い処理を一行で書く必要があるときに、 パイプ演算子を使って書く方が格段にコーディングが楽になるということである。
Tip
パイプ演算子を使うと、コンソールでの一行コード(ワンライナー)の記述が楽。
Sessioninfo
sessionInfo()R version 4.3.2 (2023-10-31)
Platform: aarch64-apple-darwin20 (64-bit)
Running under: macOS Ventura 13.1
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.11.0
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
time zone: Asia/Tokyo
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] ggplot2_3.5.1
loaded via a namespace (and not attached):
[1] vctrs_0.6.5 cli_3.6.3 knitr_1.48 rlang_1.1.4
[5] xfun_0.46 forcats_1.0.0 generics_0.1.3 jsonlite_1.8.8
[9] labeling_0.4.3 glue_1.7.0 colorspace_2.1-1 htmltools_0.5.7
[13] scales_1.3.0 fansi_1.0.6 rmarkdown_2.25 grid_4.3.2
[17] evaluate_0.24.0 munsell_0.5.1 tibble_3.2.1 fastmap_1.1.1
[21] yaml_2.3.9 lifecycle_1.0.4 compiler_4.3.2 dplyr_1.1.4
[25] htmlwidgets_1.6.4 pkgconfig_2.0.3 farver_2.1.2 digest_0.6.34
[29] R6_2.5.1 tidyselect_1.2.1 utf8_1.2.4 pillar_1.9.0
[33] magrittr_2.0.3 withr_3.0.0 tools_4.3.2 gtable_0.3.5