library(ggplot2)Rのtidyverseで行う操作をPythonで書くとするとどうなるかを自分用にメモしておく。
データフレームの操作を行うライブラリとして、pandasとpolarsを使用した場合をそれぞれ書いてみる。
GitHub - pandas-dev/pandas: Flexible and powerful data analysis / manipulation library for Python, providing labeled data structures similar to R data.frame objects, statistical functions, and much more
Flexible and powerful data analysis / manipulation library for Python, providing labeled data structures similar to R data.frame objects, statistical functions, and much more - pandas-dev/pandas
 https://github.com/pandas-dev/pandas
https://github.com/pandas-dev/pandas
Polars
DataFrames for the new era
 https://pola.rs/
https://pola.rs/

準備
ライブラリの読み込み(必要であれば)
ライブラリの読み込み
import pandas as pd
import numpy as np
import polars as pl
import polars.selectors as cs
import matplotlib.pyplot as plt
from matplotlib.figure import Figure
from plotnine import ggplot, aes, geom_point
import seaborn.objects as so
import session_infoCode
# qmdだとなぜかpolarsのデータフレームがHTML形式でprintされるので、
# pl.DataFrameの_repr_html_をオーバーライドしておく
pl.DataFrame._repr_html_ = print
# polarsのデータフレームの表示設定をシンプルにする
(pl.Config
.set_tbl_formatting(format='NOTHING')
.set_tbl_hide_dtype_separator(True))tibble
tibble, as_tibble
データフレームの初期化方法。
# 直接作る
tibble::tibble(
seisu = 0:4,
komoji = letters[1:5]
)# A tibble: 5 × 2
seisu komoji
<int> <chr>
1 0 a
2 1 b
3 2 c
4 3 d
5 4 e # listなど他のデータ型から変換
list(seisu = 0:4, komoji = letters[1:5]) |>
tibble::as_tibble()# A tibble: 5 × 2
seisu komoji
<int> <chr>
1 0 a
2 1 b
3 2 c
4 3 d
5 4 e d = {
'seisu':[i for i in range(5)],
'komoji':[i for i in 'abcde']
}
# 辞書から作る
pd.DataFrame(d) seisu komoji
0 0 a
1 1 b
2 2 c
3 3 d
4 4 e# リストから作る
pd.DataFrame([[i, j] for i,j in zip(d['seisu'], d['komoji'])], columns=d.keys()) seisu komoji
0 0 a
1 1 b
2 2 c
3 3 d
4 4 ed = {
'seisu':[i for i in range(5)],
'komoji':[i for i in 'abcde']
}
# 辞書から作る
pl.DataFrame(d)shape: (5, 2)
seisu komoji
i64 str
0 a
1 b
2 c
3 d
4 e # リストから作る
pl.DataFrame([d['seisu'], d['komoji']], schema=d.keys())shape: (5, 2)
seisu komoji
i64 str
0 a
1 b
2 c
3 d
4 e # pandasとはデータの持ち方が違うので元データが行方向の場合はorient='row'を指定する
pl.DataFrame([[i, j] for i,j in zip(d['seisu'], d['komoji'])],
schema=d.keys(), orient='row')shape: (5, 2)
seisu komoji
i64 str
0 a
1 b
2 c
3 d
4 e readr
read_csv
CSVファイルからのデータ読み込み。使用するCSVファイルは以下。
Code
cat << EOF > data.csv
"seisu","jissu","oomoji","komoji"
0,0.0,"A","a"
1,1.0,"A","b"
2,2.0,"B","c"
3,3.0,"B","d"
4,4.0,"C","e"
5,5.0,"D","f"
EOF# readr::read_csvで読み込み。デフォルトだと整数も実数で読み込まれるのでデータ型を指定した。
df <- readr::read_csv("data.csv", col_types = "idcc")
df# A tibble: 6 × 4
seisu jissu oomoji komoji
<int> <dbl> <chr> <chr>
1 0 0 A a
2 1 1 A b
3 2 2 B c
4 3 3 B d
5 4 4 C e
6 5 5 D f df_pd = pd.read_csv('data.csv')
df_pd seisu jissu oomoji komoji
0 0 0.0 A a
1 1 1.0 A b
2 2 2.0 B c
3 3 3.0 B d
4 4 4.0 C e
5 5 5.0 D fdf_pl = pl.read_csv('data.csv')
df_plshape: (6, 4)
seisu jissu oomoji komoji
i64 f64 str str
0 0.0 A a
1 1.0 A b
2 2.0 B c
3 3.0 B d
4 4.0 C e
5 5.0 D f other formats
# TSV
df |> readr::write_tsv("data.tsv.gz")
readr::read_tsv("data.tsv.gz")
# PARQUET (arrowパッケージを利用)
df |> arrow::write_parquet("data.parquet")
arrow::read_parquet("data.parquet")# TSV
df_pd.to_csv('data.tsv.gz', sep='\t', index=False)
pd.read_table("data.tsv.gz", delimiter='\t')
# PARQUET
df_pd.to_parquet('data.parquet') # qmdのrender時にpyarrow.lib.ArrowKeyErrorが出る
pd.read_parquet("data.parquet")# TSV
df_pl.write_csv('data.tsv.gz', separator='\t')
pl.read_csv("data.tsv.gz", separator='\t')
# PARQUET
df_pl.write_parquet('data.parquet')
pl.read_parquet("data.parquet")dplyr
select
列の選択。
# 列のインデックス、列名で選択
df |> dplyr::select(1, oomoji)# A tibble: 6 × 2
seisu oomoji
<int> <chr>
1 0 A
2 1 A
3 2 B
4 3 B
5 4 C
6 5 D # 列のデータ型で選択
df |> dplyr::select(tidyselect::where(is.numeric))# A tibble: 6 × 2
seisu jissu
<int> <dbl>
1 0 0
2 1 1
3 2 2
4 3 3
5 4 4
6 5 5# 列名で選択
df_pd.loc[:, ['seisu', 'oomoji']] seisu oomoji
0 0 A
1 1 A
2 2 B
3 3 B
4 4 C
5 5 Ddf_pd.drop(['jissu', 'komoji'], axis=1) seisu oomoji
0 0 A
1 1 A
2 2 B
3 3 B
4 4 C
5 5 D# 列のデータ型で選択
df_pd.select_dtypes('number') seisu jissu
0 0 0.0
1 1 1.0
2 2 2.0
3 3 3.0
4 4 4.0
5 5 5.0# 列のインデックス、列名で選択
df_pl.select(1, 'oomoji')shape: (6, 2)
literal oomoji
i32 str
1 A
1 A
1 B
1 B
1 C
1 D # 列のデータ型で選択
df_pl.select(cs.numeric())shape: (6, 2)
seisu jissu
i64 f64
0 0.0
1 1.0
2 2.0
3 3.0
4 4.0
5 5.0 mutate
新規列の追加、既存列の書き換え
df |> dplyr::mutate(seisu=seisu / 2, nibai = jissu * 2)# A tibble: 6 × 5
seisu jissu oomoji komoji nibai
<dbl> <dbl> <chr> <chr> <dbl>
1 0 0 A a 0
2 0.5 1 A b 2
3 1 2 B c 4
4 1.5 3 B d 6
5 2 4 C e 8
6 2.5 5 D f 10df |> dplyr::mutate(dplyr::across(
.cols = 1:2,
.fns = list(nibai = ~ . * 2, hanbun = ~ . / 2),
.names = "{.col}_{.fn}"
))# A tibble: 6 × 8
seisu jissu oomoji komoji seisu_nibai seisu_hanbun jissu_nibai jissu_hanbun
<int> <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 0 0 A a 0 0 0 0
2 1 1 A b 2 0.5 2 0.5
3 2 2 B c 4 1 4 1
4 3 3 B d 6 1.5 6 1.5
5 4 4 C e 8 2 8 2
6 5 5 D f 10 2.5 10 2.5df_pd.assign(seisu=lambda df: df.seisu/2, nibai=lambda df: df.jissu*2) seisu jissu oomoji komoji nibai
0 0.0 0.0 A a 0.0
1 0.5 1.0 A b 2.0
2 1.0 2.0 B c 4.0
3 1.5 3.0 B d 6.0
4 2.0 4.0 C e 8.0
5 2.5 5.0 D f 10.0pd.concat(
[df_pd,
(df_pd.select_dtypes('number').map(lambda x: x*2)
.rename(lambda x: x+'_nibai', axis=1)),
(df_pd.select_dtypes('number').map(lambda x: x/2)
.rename(lambda x: x+'_hanbun', axis=1))
],
axis=1
) seisu jissu oomoji ... jissu_nibai seisu_hanbun jissu_hanbun
0 0 0.0 A ... 0.0 0.0 0.0
1 1 1.0 A ... 2.0 0.5 0.5
2 2 2.0 B ... 4.0 1.0 1.0
3 3 3.0 B ... 6.0 1.5 1.5
4 4 4.0 C ... 8.0 2.0 2.0
5 5 5.0 D ... 10.0 2.5 2.5
[6 rows x 8 columns]pd.concat(
[df_pd,
(df_pd.select_dtypes('number')
.apply([lambda x: x*2, lambda x: x/2]))
],
axis=1
) seisu jissu oomoji ... (seisu, <lambda>) (jissu, <lambda>) (jissu, <lambda>)
0 0 0.0 A ... 0.0 0.0 0.0
1 1 1.0 A ... 0.5 2.0 0.5
2 2 2.0 B ... 1.0 4.0 1.0
3 3 3.0 B ... 1.5 6.0 1.5
4 4 4.0 C ... 2.0 8.0 2.0
5 5 5.0 D ... 2.5 10.0 2.5
[6 rows x 8 columns]df_pl.with_columns((pl.col("jissu") * 2).alias("nibai"))shape: (6, 5)
seisu jissu oomoji komoji nibai
i64 f64 str str f64
0 0.0 A a 0.0
1 1.0 A b 2.0
2 2.0 B c 4.0
3 3.0 B d 6.0
4 4.0 C e 8.0
5 5.0 D f 10.0 (df_pl
.with_columns(
(cs.numeric() * 2).name.suffix("_nibai"),
(cs.numeric() / 2).name.suffix("_hanbun")
)
)shape: (6, 8)
seisu jissu oomoji komoji seisu_nibai jissu_nibai seisu_hanbun jissu_hanbun
i64 f64 str str i64 f64 f64 f64
0 0.0 A a 0 0.0 0.0 0.0
1 1.0 A b 2 2.0 0.5 0.5
2 2.0 B c 4 4.0 1.0 1.0
3 3.0 B d 6 6.0 1.5 1.5
4 4.0 C e 8 8.0 2.0 2.0
5 5.0 D f 10 10.0 2.5 2.5 filter
条件に一致する行を抽出。
df |> dplyr::filter(jissu >= 2)# A tibble: 4 × 4
seisu jissu oomoji komoji
<int> <dbl> <chr> <chr>
1 2 2 B c
2 3 3 B d
3 4 4 C e
4 5 5 D f df |> dplyr::filter(oomoji %in% c("A", "B", "C"))# A tibble: 5 × 4
seisu jissu oomoji komoji
<int> <dbl> <chr> <chr>
1 0 0 A a
2 1 1 A b
3 2 2 B c
4 3 3 B d
5 4 4 C e df_pd.loc[df_pd['jissu'] >= 2, :] seisu jissu oomoji komoji
2 2 2.0 B c
3 3 3.0 B d
4 4 4.0 C e
5 5 5.0 D fdf_pd.query("oomoji in ['A', 'B', 'C']") seisu jissu oomoji komoji
0 0 0.0 A a
1 1 1.0 A b
2 2 2.0 B c
3 3 3.0 B d
4 4 4.0 C edf_pl.filter(pl.col("jissu") >= 2)shape: (4, 4)
seisu jissu oomoji komoji
i64 f64 str str
2 2.0 B c
3 3.0 B d
4 4.0 C e
5 5.0 D f df_pl.filter(pl.col("oomoji").is_in(['A', 'B', 'C']))shape: (5, 4)
seisu jissu oomoji komoji
i64 f64 str str
0 0.0 A a
1 1.0 A b
2 2.0 B c
3 3.0 B d
4 4.0 C e arrange
行の並べ替え。
df |> dplyr::arrange(oomoji, dplyr::desc(seisu))# A tibble: 6 × 4
seisu jissu oomoji komoji
<int> <dbl> <chr> <chr>
1 1 1 A b
2 0 0 A a
3 3 3 B d
4 2 2 B c
5 4 4 C e
6 5 5 D f df_pd.sort_values(['oomoji', 'seisu'], ascending=[True, False]) seisu jissu oomoji komoji
1 1 1.0 A b
0 0 0.0 A a
3 3 3.0 B d
2 2 2.0 B c
4 4 4.0 C e
5 5 5.0 D fdf_pl.sort(by = ['oomoji', 'seisu'], descending=[False, True])shape: (6, 4)
seisu jissu oomoji komoji
i64 f64 str str
1 1.0 A b
0 0.0 A a
3 3.0 B d
2 2.0 B c
4 4.0 C e
5 5.0 D f group_by -> summarise
変数でグループ化して集約する。
df |>
dplyr::summarise(
.by = oomoji,
seisu_gokei = sum(seisu)
)# A tibble: 4 × 2
oomoji seisu_gokei
<chr> <int>
1 A 1
2 B 5
3 C 4
4 D 5(df_pd
.groupby('oomoji')
.agg(seisu_gokei=('seisu', np.sum))
.reset_index())<string>:3: FutureWarning: The provided callable <function sum at 0x11239ff60> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
oomoji seisu_gokei
0 A 1
1 B 5
2 C 4
3 D 5(df_pl
.group_by('oomoji')
.agg(pl.col('seisu').sum().alias('seisu_gokei')))shape: (4, 2)
oomoji seisu_gokei
str i64
D 5
A 1
C 4
B 5 distinct
重複のない観測データ(行)のみ残す。
df |>
dplyr::select(oomoji) |>
dplyr::distinct()# A tibble: 4 × 1
oomoji
<chr>
1 A
2 B
3 C
4 D (df_pd
.loc[:, ['oomoji']] # 列はリストで指定しないとpd.Seriesになってしまう
.drop_duplicates()) oomoji
0 A
2 B
4 C
5 D(df_pl
.select(pl.col('oomoji'))
.unique())shape: (4, 1)
oomoji
str
C
B
A
D glimpse
列が多数ある場合に見やすく表示する。
df |> dplyr::group_by(oomoji) |> dplyr::glimpse()Rows: 6
Columns: 4
Groups: oomoji [4]
$ seisu <int> 0, 1, 2, 3, 4, 5
$ jissu <dbl> 0, 1, 2, 3, 4, 5
$ oomoji <chr> "A", "A", "B", "B", "C", "D"
$ komoji <chr> "a", "b", "c", "d", "e", "f"pd.DataFrameにはglimpseメソッドはない。
def glimpse(df):
print(f"Rows: {df.shape[0]}")
print(f"Columns: {df.shape[1]}")
for col in df.columns:
print(f"$ {col} <{df[col].dtype}> {df[col].head().values}")
glimpse(df_pd)Rows: 6
Columns: 4
$ seisu <int64> [0 1 2 3 4]
$ jissu <float64> [0. 1. 2. 3. 4.]
$ oomoji <object> ['A' 'A' 'B' 'B' 'C']
$ komoji <object> ['a' 'b' 'c' 'd' 'e']Above codes are borrowed from this stackoverflow
# pl.DataFrameはglimpseメソッドがあるがgroup_byすると使えない
df_pl.glimpse()Rows: 6
Columns: 4
$ seisu <i64> 0, 1, 2, 3, 4, 5
$ jissu <f64> 0.0, 1.0, 2.0, 3.0, 4.0, 5.0
$ oomoji <str> 'A', 'A', 'B', 'B', 'C', 'D'
$ komoji <str> 'a', 'b', 'c', 'd', 'e', 'f'*_join
join関数
dfl <- df[c(1,3,5), c(1,3)]
dfr <- df[c(2,4,6), c(2,3)]
dfl |> dplyr::left_join(dfr, by = "oomoji")# A tibble: 3 × 3
seisu oomoji jissu
<int> <chr> <dbl>
1 0 A 1
2 2 B 3
3 4 C NAdfl |> dplyr::right_join(dfr, by = "oomoji")# A tibble: 3 × 3
seisu oomoji jissu
<int> <chr> <dbl>
1 0 A 1
2 2 B 3
3 NA D 5dfl |> dplyr::inner_join(dfr, by = "oomoji")# A tibble: 2 × 3
seisu oomoji jissu
<int> <chr> <dbl>
1 0 A 1
2 2 B 3dfl |> dplyr::full_join(dfr, by = "oomoji")# A tibble: 4 × 3
seisu oomoji jissu
<int> <chr> <dbl>
1 0 A 1
2 2 B 3
3 4 C NA
4 NA D 5dfl_pd = df_pd.loc[[0,2,4], ['seisu','oomoji']]
dfr_pd = df_pd.loc[[1,3,5], ['jissu','oomoji']]
dfl_pd.merge(dfr_pd, on='oomoji', how='left') seisu oomoji jissu
0 0 A 1.0
1 2 B 3.0
2 4 C NaNdfl_pd.merge(dfr_pd, on='oomoji', how='right') seisu oomoji jissu
0 0.0 A 1.0
1 2.0 B 3.0
2 NaN D 5.0dfl_pd.merge(dfr_pd, on='oomoji', how='inner') seisu oomoji jissu
0 0 A 1.0
1 2 B 3.0dfl_pd.merge(dfr_pd, on='oomoji', how='outer') seisu oomoji jissu
0 0.0 A 1.0
1 2.0 B 3.0
2 4.0 C NaN
3 NaN D 5.0dfl_pl = df_pl[[0,2,4], ['seisu','oomoji']]
dfr_pl = df_pl[[1,3,5], ['jissu','oomoji']]
dfl_pl.join(dfr_pl, on='oomoji', how='left')shape: (3, 3)
seisu oomoji jissu
i64 str f64
0 A 1.0
2 B 3.0
4 C null dfl_pl.join(dfr_pl, on='oomoji', how='right')shape: (3, 3)
seisu jissu oomoji
i64 f64 str
0 1.0 A
2 3.0 B
null 5.0 D dfl_pl.join(dfr_pl, on='oomoji', how='inner')shape: (2, 3)
seisu oomoji jissu
i64 str f64
0 A 1.0
2 B 3.0 dfl_pl.join(dfr_pl, on='oomoji', how='full')shape: (4, 4)
seisu oomoji jissu oomoji_right
i64 str f64 str
0 A 1.0 A
2 B 3.0 B
null null 5.0 D
4 C null null dfl_pl.join(dfr_pl, on='oomoji', how='full', coalesce=True)shape: (4, 3)
seisu oomoji jissu
i64 str f64
0 A 1.0
2 B 3.0
null D 5.0
4 C null tidyr
pivot_longer
データフレームを縦長に変形
df |> tidyr::pivot_longer(cols = 1:2)# A tibble: 12 × 4
oomoji komoji name value
<chr> <chr> <chr> <dbl>
1 A a seisu 0
2 A a jissu 0
3 A b seisu 1
4 A b jissu 1
5 B c seisu 2
6 B c jissu 2
7 B d seisu 3
8 B d jissu 3
9 C e seisu 4
10 C e jissu 4
11 D f seisu 5
12 D f jissu 5df_pd.melt(id_vars=['oomoji', 'komoji'], value_vars=['seisu', 'jissu']) oomoji komoji variable value
0 A a seisu 0.0
1 A b seisu 1.0
2 B c seisu 2.0
3 B d seisu 3.0
4 C e seisu 4.0
5 D f seisu 5.0
6 A a jissu 0.0
7 A b jissu 1.0
8 B c jissu 2.0
9 B d jissu 3.0
10 C e jissu 4.0
11 D f jissu 5.0df_pl.unpivot(on=['seisu', 'jissu'], index=['oomoji', 'komoji'])shape: (12, 4)
oomoji komoji variable value
str str str f64
A a seisu 0.0
A b seisu 1.0
B c seisu 2.0
B d seisu 3.0
C e seisu 4.0
… … … …
A b jissu 1.0
B c jissu 2.0
B d jissu 3.0
C e jissu 4.0
D f jissu 5.0 pivot_wider
データフレームを横長に変形
df |>
tidyr::pivot_longer(cols = 1:2) |>
tidyr::pivot_wider()# A tibble: 6 × 4
oomoji komoji seisu jissu
<chr> <chr> <dbl> <dbl>
1 A a 0 0
2 A b 1 1
3 B c 2 2
4 B d 3 3
5 C e 4 4
6 D f 5 5(df_pd
.melt(id_vars=['oomoji', 'komoji'], value_vars=['seisu', 'jissu'])
.pivot(columns='variable', index=['oomoji', 'komoji'], values='value')
.reset_index())variable oomoji komoji jissu seisu
0 A a 0.0 0.0
1 A b 1.0 1.0
2 B c 2.0 2.0
3 B d 3.0 3.0
4 C e 4.0 4.0
5 D f 5.0 5.0(df_pl
.unpivot(on=['seisu', 'jissu'], index=['oomoji', 'komoji'])
.pivot('variable', index=['oomoji', 'komoji'], values='value'))shape: (6, 4)
oomoji komoji seisu jissu
str str f64 f64
A a 0.0 0.0
A b 1.0 1.0
B c 2.0 2.0
B d 3.0 3.0
C e 4.0 4.0
D f 5.0 5.0 ggplot2
プロットが一つの場合
Code
theme_matplotlib_like <- function() {
list(
theme(
panel.background = element_rect(fill = NA, colour = "black"),
panel.grid = element_blank(),
legend.key = element_blank()
),
scale_color_viridis_d(option = "E"),
scale_fill_viridis_d(option = "E")
)
}df |>
ggplot(aes(seisu, jissu)) +
geom_point(aes(color = oomoji, shape = komoji), size = 5) +
theme_matplotlib_like()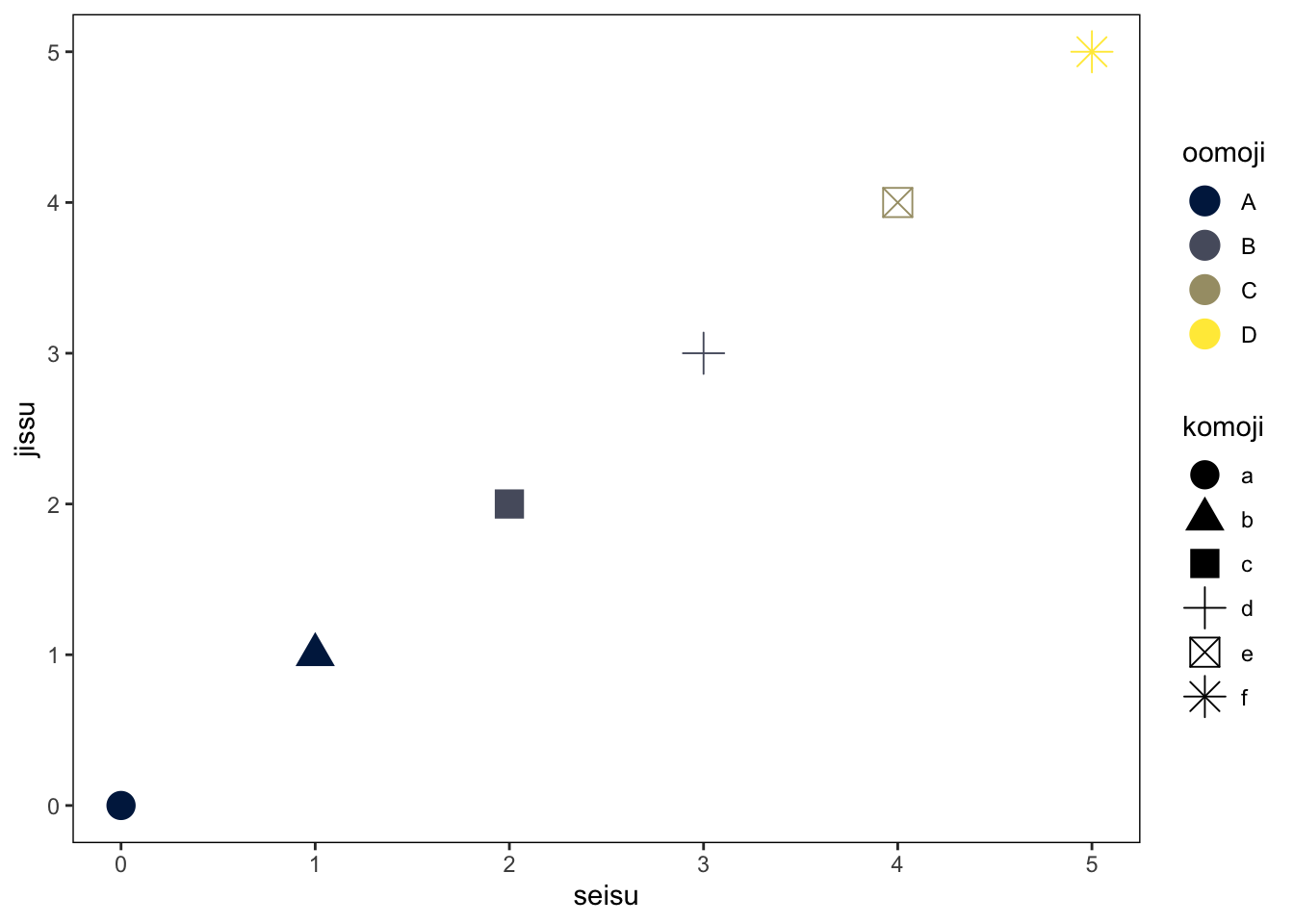
Code
cmap = plt.get_cmap("cividis")
df_pl_plot = (
df_pl.with_columns(
pl.col("oomoji")
.rank("dense")
.cast(pl.Int64)
.alias("oomoji_color")
).with_columns(
(pl.col("oomoji_color") / pl.col("oomoji_color").max())
.map_elements(lambda x: cmap(x), return_dtype=pl.Object)
)
)fig, ax = plt.subplots(1, 1)
_ = ax.scatter("seisu", "jissu", c="oomoji_color", s=100, data=df_pl_plot)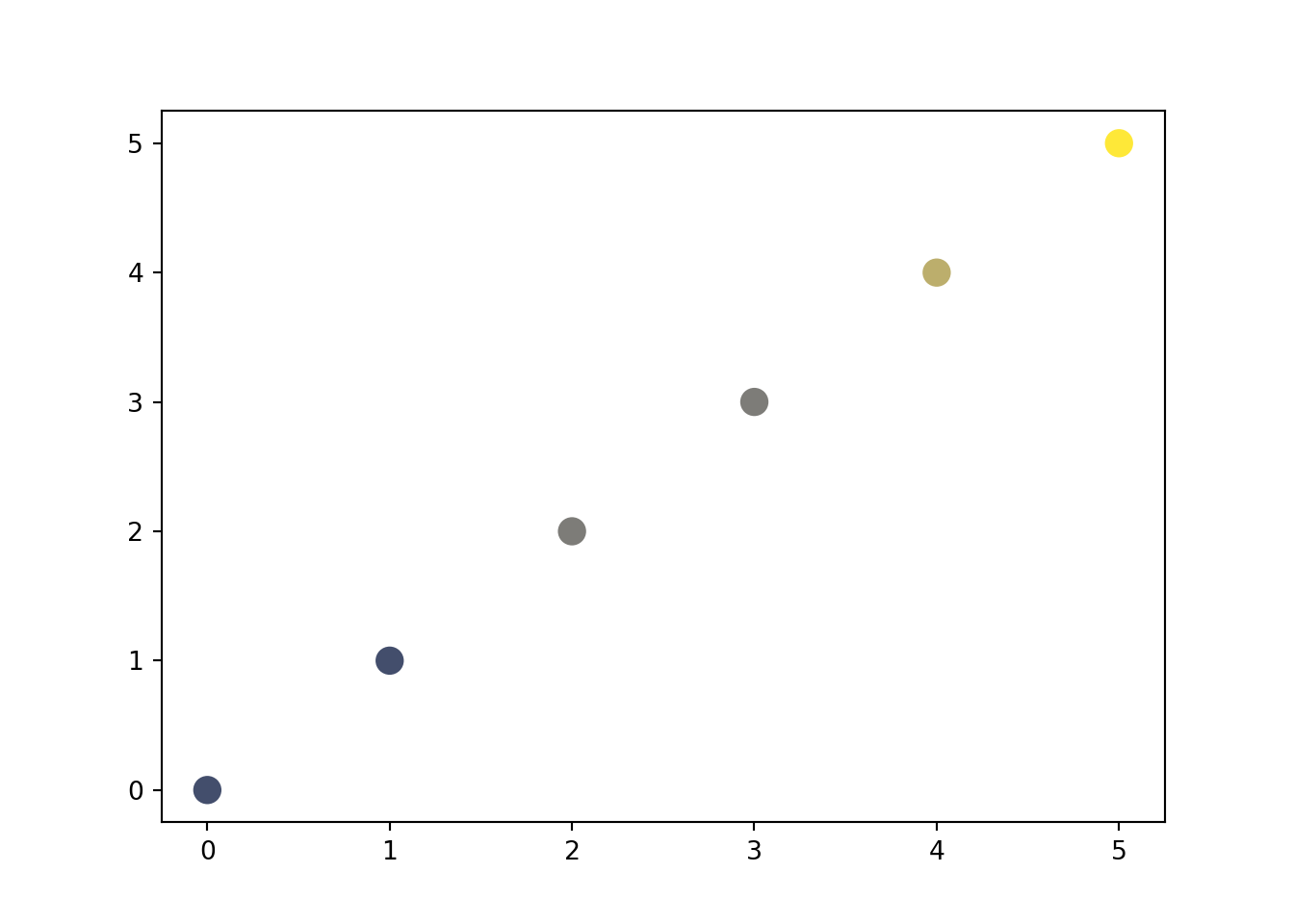
ほぼggplot2と同じような感じにかける。
(
ggplot(df_pl_plot, aes('seisu', 'jissu'))
+ geom_point(aes(color = 'oomoji', shape = 'komoji'), size = 5)
).show()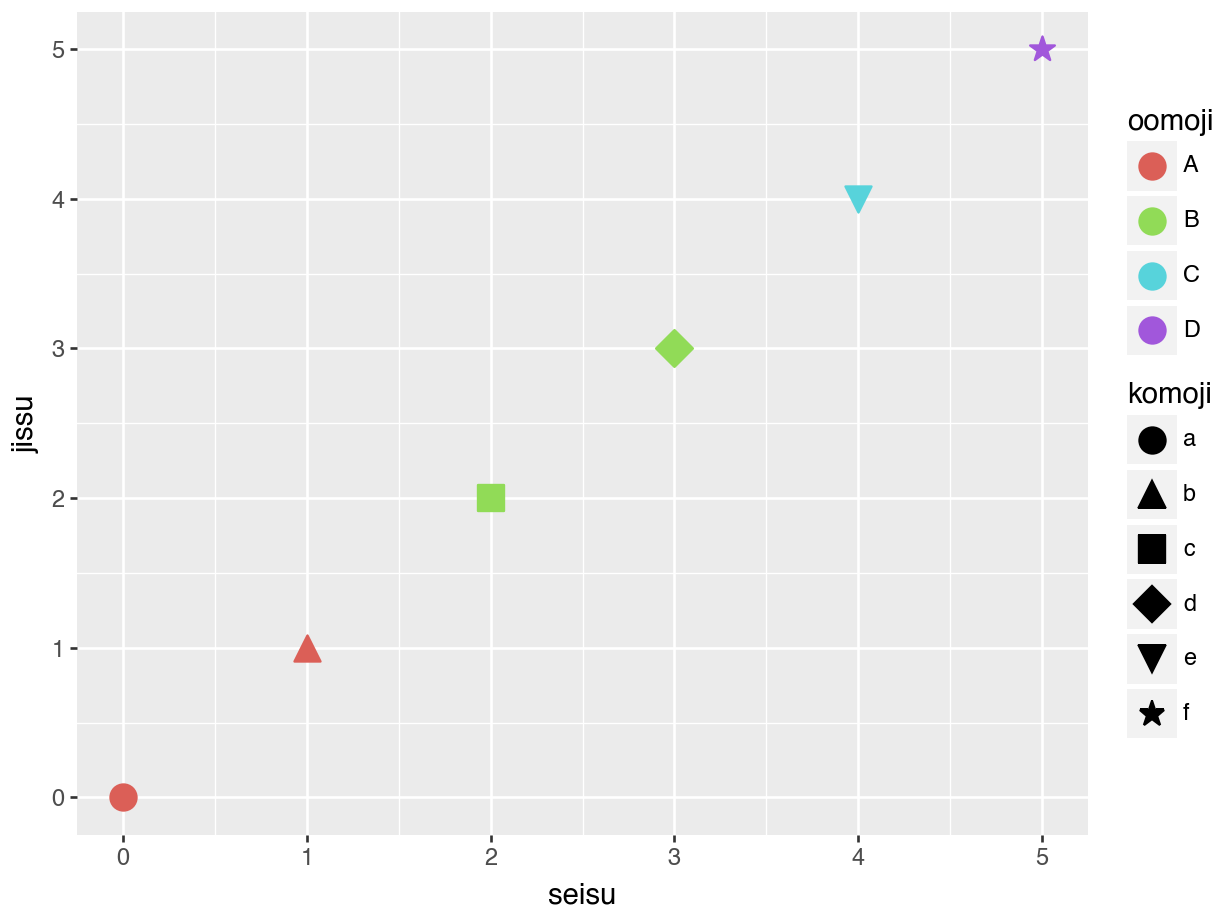
(
so.Plot(data=df_pl_plot.to_pandas(), x='seisu', y='jissu')
.add(so.Dot(pointsize=10), color='oomoji', marker='komoji')
).show()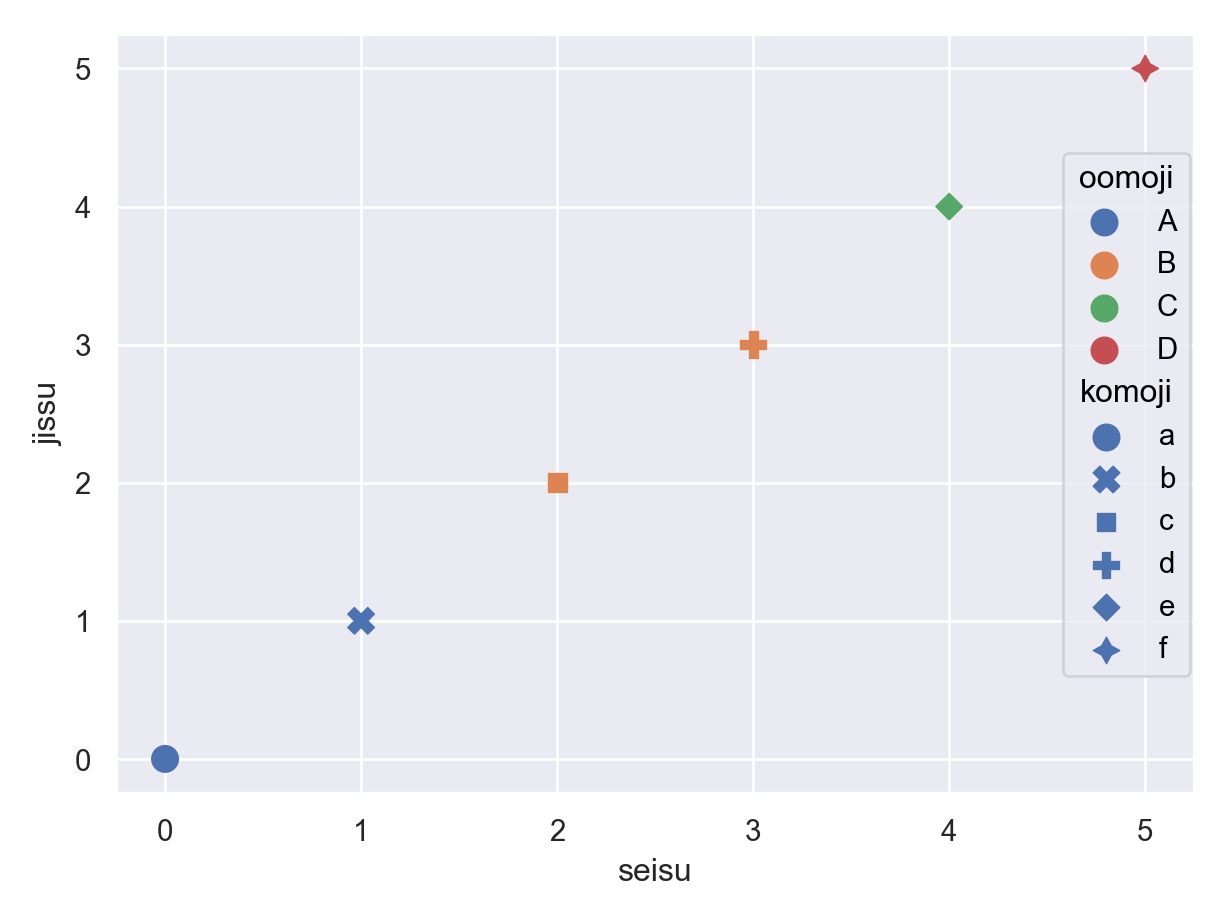
複数のプロットを組み合わせる
gp1 <- df |>
ggplot(aes(seisu, jissu)) +
geom_point(aes(color = oomoji, shape = komoji), size = 5)
gp2 <- df |>
ggplot(aes(komoji, jissu)) +
geom_col(aes(fill = oomoji)) +
scale_y_continuous(expand = expansion(c(0, 0.1)))
gp3 <- df |>
ggplot(aes(komoji, jissu)) +
geom_line(aes(group=""))
patchwork::wrap_plots(gp1, gp2, gp3, ncol = 3, guides = "collect") &
theme_matplotlib_like() &
theme(legend.direction = "horizontal")
fig, axs = plt.subplots(1, 3)
sc = axs[0].scatter('seisu', 'jissu', c='oomoji_color', s=100, data=df_pl_plot)
# produce a legend with the unique colors from the scatter
legend1 = axs[0].legend(*sc.legend_elements(), loc="lower left")
axs[0].add_artist(legend1)
axs[0].legend()
axs[1].bar('komoji', 'jissu', color='oomoji_color', data=df_pl_plot)
axs[1].legend()
axs[2].plot(df_pl_plot['komoji'], df_pl_plot['jissu'])
axs[2].legend()
別パターン
fig = plt.figure()
ax1 = fig.add_subplot(131)
ax1.scatter('seisu', 'jissu', c='oomoji_color', s=100, data=df_pl_plot)
ax2 = fig.add_subplot(132)
ax2.bar('komoji', 'jissu', color='oomoji_color', data=df_pl_plot)
ax3 = fig.add_subplot(133)
ax3.plot(df_pl_plot['komoji'], df_pl_plot['jissu'])
patchworklib v0.6.5を使うとplotnine v0.13.6まではできたようだが、 plotnine v0.14.1では現状未対応となっている。
so1 = (
so.Plot(df_pl_plot.to_pandas(), x='seisu', y='jissu')
.add(so.Dot(pointsize=6), color='oomoji', marker='komoji')
.scale()
)
so2 = (
so.Plot(df_pl_plot.to_pandas(), x='komoji', y='jissu')
.add(so.Bar(), color='oomoji')
.scale()
)
so3 = (
so.Plot(df_pl_plot.to_pandas(), x='komoji', y='jissu')
.add(so.Line())
)
f = plt.figure(clear=True, layout='constrained')
sfs = f.subfigures(1, 4, width_ratios=(1,1,1,0.5))
for sf, soi in zip(sfs, [so1, so2, so3]):
_ = soi.on(sf).plot()
pos = ["upper center", "center", "lower center"]
i = 0
while True:
try:
l = f.legends.pop()
except:
break
_ = sfs[-1].legend(l.legend_handles, [t.get_text() for t in l.texts], loc=pos[i])
i += 1
複数のlegendをうまく取り扱うことができない。 まず普通にするとlegendが見切れて表示されないし、 ここで示すようにlegendを取り出して表示するようにしてもmarkerのlegendが消えてしまって表示できない。
感想
pandasに比べると、mutate関連の操作などではpolarsの方が簡潔にかけるように感じた。
参考
python pandas と R tidyverseの比較 - Qiita
Rのtidyverseパッケージ群は、データの操作や可視化を簡潔で一貫した記述で行うことができる非常に優れたツールで、私も愛してやみません。 しかし、最近はシステムにモデルを組み込んだり、ディープラーニングライブラリを試したりするために、Pythonそしてpandasパッケ...


R/tidyverseとPython/polarsの比較 - Qiita
はじめに 備忘として、データフレーム操作におけるRのtidyverse (主にdplyr)からpythonのpolarsへの書き換えを順次更新していきます。 Rからpythonに移行したものの、pandasが嫌いで使いたくない人向けです。 準備 パッケージインストール...

Sessioninfo
sessionInfo()R version 4.3.2 (2023-10-31)
Platform: aarch64-apple-darwin20 (64-bit)
Running under: macOS Ventura 13.1
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.11.0
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
time zone: Asia/Tokyo
tzcode source: internal
attached base packages:
[1] stats graphics grDevices datasets utils methods base
other attached packages:
[1] ggplot2_3.5.1
loaded via a namespace (and not attached):
[1] bit_4.0.5 Matrix_1.6-1.1 gtable_0.3.5 jsonlite_1.8.8
[5] crayon_1.5.2 dplyr_1.1.4 compiler_4.3.2 renv_1.0.10
[9] tidyselect_1.2.1 Rcpp_1.0.13 parallel_4.3.2 tidyr_1.3.1
[13] scales_1.3.0 png_0.1-8 yaml_2.3.9 fastmap_1.1.1
[17] reticulate_1.39.0 lattice_0.21-9 readr_2.1.5 R6_2.5.1
[21] patchwork_1.2.0 labeling_0.4.3 generics_0.1.3 knitr_1.48
[25] tibble_3.2.1 munsell_0.5.1 pillar_1.9.0 tzdb_0.4.0
[29] rlang_1.1.4 utf8_1.2.4 xfun_0.46 bit64_4.0.5
[33] viridisLite_0.4.2 cli_3.6.3 withr_3.0.0 magrittr_2.0.3
[37] digest_0.6.34 grid_4.3.2 vroom_1.6.5 hms_1.1.3
[41] lifecycle_1.0.4 vctrs_0.6.5 evaluate_0.24.0 glue_1.7.0
[45] farver_2.1.2 fansi_1.0.6 colorspace_2.1-1 purrr_1.0.2
[49] rmarkdown_2.25 tools_4.3.2 pkgconfig_2.0.3 htmltools_0.5.7 session_info.show()